




生成AIの将来を語る場では、喝采と酷評が隣り合わせになる。過剰な期待で舞い上がる人と、無駄に厳しい判定を下す人が同居しているのだ。どちらも極論であり、冷静な数字や分析に基づく判断こそが必要だと私は考える。
Twitter(X)などの議論を見ているとAIに限らず、政治に関する話題なども、極論や、all-or-nothingの二項対立ゼロイチ思考の人ばかりでウンザリしたりもするが、今の世の中の特徴なのだろう。ついて行けないし、行く気もなし。世の中はグラデーションと相互の譲り合いでできているのだ。
話を戻そう。
私は講演のたびに、「AIなら何でも解決できる」と信じる人と、「どうせ大した役に立たない」と突き放す人が同時に手を挙げる光景を見てきた。どちらの極論も、数字を知らずに雰囲気で語っている点では同じだ。期待や恐怖ではなくハードウェアの伸び、アルゴリズム効率、インフラの制約という“動かせない事実”に目を向ける。結果として「数年先すら読みきれない」ことが浮かび上がるはずだ。
目次
AI計算力の爆発的増加と、立ちはだかる物理的な壁
AIを鍛える計算量は、およそ3か月半ごとに2倍になる…と言われても、まぁピンと来にくいだろう。そこで、スマートフォンの進化に置き換えてみよう。
ふつう最新機種に買い替えても、カメラやCPU性能は「去年より20~30%良くなった」程度だろう。ところがAIの世界では、その伸び幅が4倍速でやって来る。もしスマートフォンが同じ曲線を描いたら、カメラ性能は1年で8倍、3年後には約160倍に達してしまう計算だ。いま撮る写真が名刺サイズだとしたら、3年後には新聞紙どころか屋外看板にも引き伸ばせる。それくらいケタ違いの伸び方だと想像してほしい。
もっとも、計算力がいくら伸びても話はそこで終わらない。学習量が 10²⁶ FLOPs を超えるとEUでは「高リスクAI」に区分され、厳しい監査と報告の義務が発生する。さらにこの規模では、1回の学習だけで小都市が1年に使う電力を消費するため、最新GPUをそろえても冷却設備や送電網が追いつかない。物理インフラそのものがブレーキとなり、3年も経たないうちにロードマップを白紙に戻さざるを得なくなる。これが「数年先を描けない」最初の理由だ。
アルゴリズムは学習時間を毎年半分にする
DeepMindの報告によれば、同じ成績を出すのに必要な計算量はおよそ8か月で半減している。たとえば今日100時間かかるトレーニングが、1年後には25時間程度で済んでしまう計算だ。
この効率化がハードの性能向上と重なると、30~60倍もの実力アップが3年間で現実になる。問題は「どのタイミングで“突然賢くなる”か」を事前に読めないこと。モデルがある大きさを超えた瞬間に急に多言語ジョークを理解する、といった“飛び級”がたびたび報告されている。こうした跳躍点が予測不能な以上、3年後を線で結ぶ意味が薄れるのである。
電力・データ・資金――三つ巴の限界
生成AIの進化は目覚ましいが、その更なる発展を持続させるためには、看過できない重要な「壁」が存在する。それが、大規模な計算能力を支える「電力」、賢くなるための学習に不可欠な「データ」、そして巨額な研究開発投資を可能にする「資金」の三つ。これら三つの要素がそれぞれ限界に近づき、複雑に絡み合いながら、AI開発の未来における大きな課題として浮上している。
電力
GPT-4でも学習1回で0.04TWh。3年後のモデルは理論上1TWhに近づくとされ、小さな国の年間消費量に匹敵する。再エネの大規模サイトや原子力を背負わないと、そもそも稼働できない。
電力やエネルギー効率については以下の記事でも触れているので、ぜひご一読ください。
生成AI時代、進化を遂げる最新技術(TTTモデルと光電融合技術)
生成AIの急成長とエネルギー消費問題:持続可能な未来への課題と解決策

データ
良質な公開テキストデータは、既に既存の大規模言語モデルの学習に広く活用され尽くしており、新規開発や性能向上のために必要な多様かつ未使用のデータソースが枯渇しつつある。このため、多くの企業は、プライバシーやセキュリティに最大限配慮しながら、保有する社内チャットログやメール、文書といった独自データの収集・整備(クレンジング)に力を入れているが、その質や量、継続的な確保には限界がある。
特に、更なるブレークスルーを目指す将来のモデルでは、現在の学習データ量をはるかに凌駕する10兆トークン規模という途方もないデータ量が必要になると予測されており、既存の現実世界データだけでは到底賄いきれない状況である。こうしたデータ飢餓とも言える状況を打開し、大規模なデータ需要を満たすためには、AI自身が生成した多様な文章や情報を、新たな学習データとして再利用する「合成データ(Synthetic Data)」の活用が避けられない重要な手法となっている。
ただし、合成データのみに依存することは、データの偏りや誤りの永続化、あるいはモデルの能力が停滞・劣化する「モデルコラプス」といった潜在的なリスクも指摘されており、データの質の確保が極めて重要な課題となっている。
資金
大規模言語モデルの開発と学習には、学習段階で膨大な計算リソース(GPUクラスターなど)の確保や高度なエンジニアリング、質の高いデータ処理などに、極めて巨額な初期投資と継続的な運用コストがかかる。GPT-4の学習にかかったコストは推定43億円とされるが、これはあくまで一つのモデル開発にかかる費用の初期段階を示すに過ぎず、更なる性能向上や大規模化を目指す次世代モデルでは、必要となる計算量とそれに伴うコストは指数関数的に増加する。
例えば、モデル性能を現在の30倍に伸ばすといった目標には、優に1000億円規模の投資が現実味を帯びてくる状況である。これほどの途方もない巨額な資金を、リターンが不確実な先端技術の研究開発投資として、単独の民間企業が継続的に投じ続けることは、財務的なリスクを考えると極めて荷が重いと言える。
そのため、今後はOpenAIとMicrosoftのような、潤沢な資金力を持つ複数の巨大テック企業や投資家が戦略的に連携し、リスクと資金的負担を分散しながら開発を進める「連合体モデル」が主流となる見込みだ。このように、開発・運用に必要な資金力の規模そのものが、AI進化のスピードと到達点を左右する、最も直接的かつ重要な限界の一つとなっていることは明白である。
これら三つの壁は 奇しくも2027年前後で同時に迫ってくると予想されている。ゆえに「3年」を境に未来の不確実性が急上昇するわけだ。
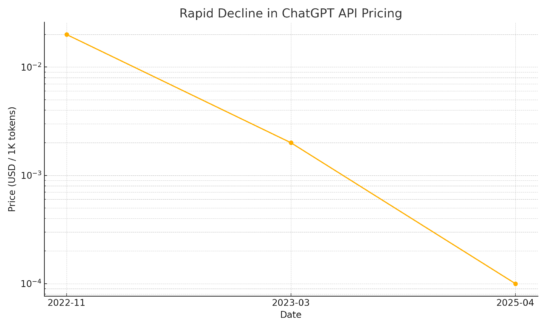
API価格が雪崩を起こすと何が変わるか
OpenAIが2022年11月に公開したChatGPT(gpt-3.5-turbo)APIは、当初1,000トークンあたり0.020ドルだった。ところが翌2023年3月の料金改定で0.002ドルへ。わずか4か月で10分の1まで下がった実例だ。携帯料金に置き換えれば、月1万円のプランが、ある日突然700円になるような急降下である。
私の現場でも、当初は赤字確定で却下したチャットボット企画が、半年後の値下げで黒字試算の認識に一変した。「価格が高いから見送る」は、もはや意思決定の根拠になりにくい。
直近の例を示すと、2025年4月15日に登場したGPT‑4.1は中央値レベルの問い合わせ処理において、GPT‑4oと比べて26%のコスト削減を実現している。特筆すべきは、プロンプトキャッシュ利用時の割引率が最大75%まで拡大された点。具体的な入力トークン単価を見ると、GPT‑4.1は100万トークンあたり2ドル、miniモデルは同0.40ドル、最も安価なnanoモデルは同0.10ドルに設定されている。さらに、Batch API経由でリクエストを処理する場合、これらの基本料金から追加で50%の割引が適用される点も大きい。
こうした料金モデルの進化によって、「コストが合わないからやめよう」という判断が一夜にして蒸発する世界が現実になりつつある。
超パーソナライズは二層構造でやって来る
「将来は一人ひとりが専用AIを持つ」と聞くと、巨大なモデルがユーザー数ぶん複製されるイメージを抱きがちだ。しかし現実解はもっとスマートなんだろうと思う。
巨大共通モデル+薄い個人適応レイヤーの二層構造は、ほぼ既定路線と見ていい。この構造は、膨大な知識と高い推論能力を持つ基盤モデルのパワーを活用しつつ、ユーザー一人ひとりの個別ニーズやプライバシーへの配慮を両立させるために重要となる。クラウド側の巨大モデルが世界のあらゆる情報に基づいた百科事典レベルの知識と高度な推論を受け持ち、その上で、端末内の比較的容量の小さな調整データ(LoRAのように数MB程度)である薄い個人適応レイヤーがユーザー固有の語彙や好み、さらには特定の文脈といったパーソナルな情報を注入し、応答をカスタマイズする役割を担う。
医療カルテのように外部へ出せない機密性の高い情報は安全な端末で処理し、プライバシーを保護したまま要約だけをクラウドに送る。そんな実装がすでに始まっているのだ。
まとめ
生成AIの進化を追っていると、未来はしばしば「バラ色」か「絶望」の二択で語られる。しかし数字を冷静に並べてみると、景色はもっと複雑だ。ハードウェアは3.4か月ごとに性能を倍化させるが、消費電力とEU規制が“ストップライン”を引き、アルゴリズムは学習効率を8か月で半減させながら、いつ創発的な跳躍を起こすか誰も読めない。そこへ電力・データ・資金という“三つ巴の壁”が2027年前後で一斉に押し寄せる。
一方で、API価格は雪崩のように下がり、昨日まで赤字だった企画が朝には黒字へ転じる。巨大モデル×軽量アダプタの二層パーソナライズが進めば、個人情報を握ったまま“共有の大脳”を使い倒す世界が整う。動力源は潤沢に、しかしブレーキも同時に強まるという、きわめて不均衡なフェーズに差し掛かったと言える。
結局のところ、3年後を完璧に描くことは難しい。必要なのは、半年ごとに環境が塗り替わる前提でプロジェクトを設計し、数字を確認しては躊躇なく方向転換できる組織文化だろう。
この“短サイクル・多層連携”を実践できるかどうかが、3年後の霧の中で生存ラインを分ける。未来を計画するより、未来に合わせて常に更新する。それが生成AI時代に最も合理的な「長期戦略」になる。が私の結論かな。



















電力やエネルギー効率の技術革新は、私がこれまで述べている内容だけではない。スーパーコンピュータの冷却技術を開発するベンチャー企業のZYRQが、台湾最大の研究開発機構である工業技術研究院ITRIと共同で「水浸」冷却システムの次世代機を開発すると言うニュースも見かけた。まだ私自身の学習が追いついていないけれども、これによってAIデータセンターの運用がより効率良くなるだけでなく、GPU製造におけるパッケージング工程の難しさからも解放されるらしい。これまでも、電気を通さない合成油やシリコンオイルに基板を浸す「液浸」方式あったらしい。油冷、水冷のバイクエンジンみたいじゃないか。この技術もワクワクさせてくれる。